How We Made Warren Better at UK Financial Questions
Off-the-shelf LLMs are not designed with UK financial regulations in mind. We gave Warren a source of truth for UK financial rules - 746 concepts, 7,753 atomic units, all sourced from gov.uk.
Prashant Khare
Prashant is a Founding AI Engineer at Meet Warren, building the AI and agentic systems behind Warren.
17 min read
2026-02-18
The Problem
Large language models are confident about UK financial regulations. They're also sometimes wrong.
Ask a frontier model for the current ISA allowance and it might give you last year's figure. Ask about the Marriage Allowance threshold and it might invent one. Ask how salary sacrifice interacts with the tapered pension annual allowance, or how much of your student loan actually comes off your payslip each month based on your repayment plan, and you'll get a fluent, plausible, and potentially incorrect answer.
The failure modes are predictable:
Outdated knowledge. UK tax thresholds, ISA allowances, pension rules, and benefit rates change every April - and sometimes mid-year via Budgets. An LLM's training data is always months behind. When allowances change, the model doesn't know - and it won't tell you it doesn't know.
Hallucinated specifics. LLMs don't say "I'm not sure." They fabricate precise numbers - a plausible-sounding threshold for the Junior ISA contribution limit, a convincing but wrong figure for the Capital Gains Tax annual exempt amount. In finance, a confidently wrong number is worse than no answer at all.
No source attribution. Even when an LLM gets the answer right, it can't tell you where the information came from. For financial regulations, provenance matters - users need to know they're getting information from gov.uk, not from a model's best guess.
These aren't edge cases. They're the default behaviour of every general-purpose LLM when applied to domain-specific, temporally-sensitive regulations.
We needed something different. Not a bigger model, not a better prompt - a structured system that treats UK financial knowledge as data, not training signal.
What We Built
Meet Warren's Knowledge Base is a concept-based retrieval system covering UK personal finance regulations. Rather than the standard RAG approach of chunking documents and searching by similarity, we structured the knowledge as concepts - semantically coherent units of knowledge - each containing atomic units with explicit temporal metadata and source attribution.
Here's what a concept looks like:
Concept: "ISA Annual Allowance"
│
├── [threshold] The annual ISA subscription limit is £20,000 for 2025-26
│ ├── temporal_status: current
│ ├── validity: 2025-04-06 → 2026-04-05
│ └── source: gov.uk/individual-savings-accounts
│
├── [rule] You can split your allowance across Cash, Stocks & Shares,
│ Innovative Finance, and Lifetime ISA
│ ├── temporal_status: current
│ └── source: gov.uk/individual-savings-accounts
│
├── [threshold] Lifetime ISA: maximum £4,000/year (counts toward £20,000)
│ ├── temporal_status: current
│ └── source: gov.uk/lifetime-isa
│
├── [eligibility] You must be 18+ for a Cash ISA, 16+ for Cash ISA only
│ ├── temporal_status: current
│ └── source: gov.uk/individual-savings-accounts
│
└── [example] "You could save £15,000 in a cash ISA and £5,000 in a
stocks and shares ISA"
└── linked to: threshold unit above
Every fact has a verifiable gov.uk source URL. Every rule carries temporal metadata - when it became valid, when it expires, whether it has been superseded by a newer regulation. The LLM receives complete, coherent knowledge rather than fragments of pages.
The Numbers
The knowledge base currently contains:
Concepts
746
Atomic units
7,753
Examples
219
Categories
23
Superseding relationships
89
Sources
gov.uk (authoritative)
These 746 concepts span the breadth of UK personal finance:
Knowledge Base Coverage
746 concepts across 23 categories of UK personal finance
Income Tax
115
Benefits – Low Income
113
Student Finance
74
Benefits – Disability
72
Benefits – Family
66
Capital Gains Tax
57
Inheritance Tax
29
Pension – Workplace
22
ISAs & Junior ISAs
21
State Pension
21
National Insurance
19
Benefits – Pension Credit
18
Benefits – Unemployment
17
Benefits – Management
17
Benefits – Bereavement
14
Benefits – Carers
12
Pension Tax
12
Self Assessment
11
Benefits – Sick Pay
9
Tax-Free Childcare
8
Tax on Savings & Investments
8
Child Benefit
7
Pensions (General)
4
Structured by Meet Warren from gov.uk sources7,753 atomic units total
The distribution reflects reality. Income Tax and Benefits are the most complex areas of UK personal finance, with dozens of interacting rules, thresholds, and eligibility criteria. ISAs, by contrast, are well-defined - fewer concepts, but each one dense with temporal variations as allowances change year to year.
Concept density varies significantly. The Pension Annual Allowance concept alone contains 51 atomic units - covering the standard allowance, tapered allowance, money purchase allowance, carry forward rules, and their historical variations. The average concept contains about 10 atomic units, but the distribution has a long tail driven by complex regulatory areas.
Construction: Key Decisions
Building the knowledge base required solving three problems: extracting structured knowledge from unstructured gov.uk pages, maintaining temporal accuracy as regulations change, and ensuring quality at scale.
Decision 1: Concepts, Not Chunks
The standard RAG approach splits documents into overlapping text chunks of fixed size and searches by embedding similarity. This works for general knowledge retrieval but creates specific problems for financial regulations:
A chunk might contain half a rule about ISA eligibility and half a rule about withdrawal penalties, making both incomplete.
Temporal information is lost - you can't distinguish current rules from historical ones when they're jumbled together in a 512-token window.
Source attribution becomes imprecise - you know roughly which page a chunk came from, but not which specific rule.
We designed concepts as the fundamental unit of retrieval. A concept groups related atomic units - individual rules, thresholds, eligibility criteria, procedures - under a shared semantic identity. When the retriever returns a concept, the LLM gets everything it needs about that topic in one coherent package: current rules, historical context, examples, and source URLs.
The trade-off is real: concepts are larger than chunks, so each one consumes more of the LLM's context window. But coherence turns out to matter more than compression. A complete concept about ISA allowances produces better answers than three overlapping chunks that each contain fragments of ISA rules.
Decision 2: LLM Extraction with a Strict Taxonomy
We use a two-pass LLM extraction strategy to convert raw gov.uk pages into structured concepts:
Pass 1 analyses the full page and extracts page-level context - what domain it covers, what audience it addresses, what time period it's relevant to.
Pass 2 extracts individual atomic units, classifying each one by type (rule, threshold, definition, procedure, eligibility), temporal validity, and concept assignment.
The key mechanism that makes this work at scale is a strict taxonomy - a predefined set of concept IDs and descriptions for each category. When processing ISA pages, the extractor doesn't invent concept names; it assigns units to a taxonomy like isa.allowance, isa.junior.eligibility, isa.lifetime.withdrawal_penalty. This prevents the drift you get when LLMs create concepts organically - where the same rule might end up as "ISA Annual Limit," "ISA Allowance Cap," or "Maximum ISA Contribution" depending on which page it was extracted from.
For new domains where we don't yet have a taxonomy, we use a bootstrap mode where the LLM proposes concept structures, which we then review and formalise before running the full extraction. This gives us the flexibility to expand into new areas without sacrificing consistency in established ones.
A crucial extraction rule: procedural sequences stay together. A multi-step process like "how to claim Marriage Allowance" is one atomic unit, not five. Splitting procedures across units would lose the sequential context that makes them useful.
Decision 3: Temporal Relationships via Superseding
Financial regulations are not static. The ISA allowance might be £20,000 this year and different next year. The Capital Gains Tax annual exempt amount changed from £12,300 to £6,000 to £3,000 over successive tax years. A knowledge base that doesn't track these temporal relationships will either serve stale information or lose historical context.
We built a three-stage superseding detection pipeline to identify and encode these relationships:
Stage 1 - Duplicate filtering. All pairs of atomic units within the same concept are compared using structural text similarity. Pairs scoring above 98% are near-identical duplicates - the same rule extracted twice from different pages, not a newer version of an older rule. These are filtered out to avoid wasting LLM calls on non-superseding pairs.
Stage 2 - Embedding similarity. Remaining pairs are compared using embedding cosine similarity. Pairs scoring below 0.80 are unlikely to be about the same rule and are discarded. This narrows thousands of potential pairs to a manageable set of candidates.
Stage 3 - LLM adjudication. Each surviving candidate pair is evaluated by an LLM: are these two units expressing the same regulation at different points in time? If so, which one is newer? The LLM determines temporal ordering and generates the superseding relationship.
Human review. Detected relationships are surfaced in a review interface where a domain expert can approve, reject, or flag for deletion. This catches the false positives that purely automated detection misses.
The result: 89 superseding relationships linking newer regulations to the ones they replaced. 22 redundant units deleted. 308 units renumbered to maintain clean sequential ordering. The older units are marked as historical with explicit superseded_date fields, so the retriever can filter appropriately - serving current regulations by default but providing historical context when specifically asked.
Decision 4: Manual Curation as a Feature
Fully automated extraction sounds appealing. In practice, LLM extraction produces good-but-imperfect output that requires human curation to reach production quality.
Our QC pipeline includes:
Deduplication - removing exact duplicate units that appear when the same rule is extracted from multiple pages, while preserving also_found_in source URLs for cross-referencing
Taxonomy alignment - moving misclassified units to their correct concepts (e.g., a general ISA rule incorrectly placed under Junior ISA)
Concept quality checks - LLM-assisted semantic analysis to verify that every unit genuinely belongs in its assigned concept
We treat manual curation as a feature, not a bug. The knowledge base covers regulations where accuracy is non-negotiable. A fully automated pipeline that's 95% correct means ~388 wrong atomic units - any one of which could give a user incorrect financial information. The curation step is what takes us from "impressive demo" to "production system."
The Retriever: Key Decisions
Having a high-quality knowledge base is necessary but not sufficient. The retrieval system - how we find the right concepts for a given user query - is equally important.
Retrieval Pipeline
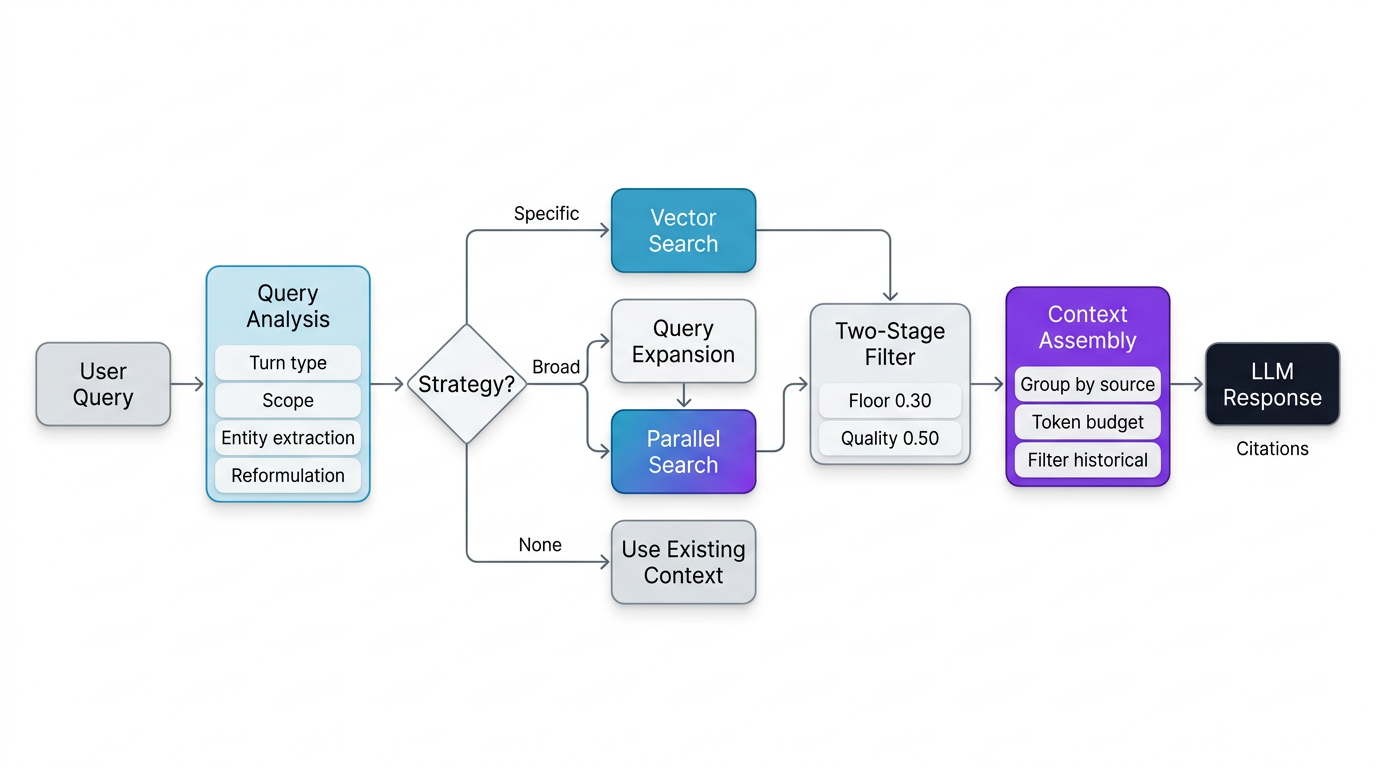
Decision 1: Query Analysis Before Retrieval
Most RAG systems embed the user's query and immediately run a similarity search. We add an analysis step first.
A lightweight model (GPT-4.1-mini) classifies each incoming query along multiple dimensions:
Turn type: New question, follow-up, or clarification?
Scope: Does the user name a specific topic ("What's the ISA allowance?") or describe a situation ("I'm saving for my first home")?
Topic shift: For follow-ups, has the user changed subjects?
Entity extraction: Age, income, relationships, goals, regions
Query reformulation: "Tell me more about that" becomes "Tell me more about the Lifetime ISA contribution limits"
This classification determines the retrieval strategy:
The "none" strategy matters. Not every message in a conversation needs a knowledge base lookup. When a user says "Can you explain that more simply?", the answer is already in context. Retrieving again wastes latency and risks introducing unrelated concepts.
Decision 2: Query Expansion for Broad Queries
When a user asks "I'm turning 55, what changes for me?" - they don't know which topics are relevant. Neither does a single embedding vector.
For broad queries, a higher-capability model (GPT-4.1) generates 3–5 specific search terms informed by the knowledge base's category structure: "pension access at age 55," "age-related tax allowances," "state pension age eligibility."
Each expanded query independently retrieves concepts via vector search - concepts, not individual facts. The results are merged by concept ID (keeping the highest similarity score when two sub-queries surface the same concept) and deduplicated. Then, during context assembly, the atomic units within each retrieved concept are extracted, filtered, and formatted for the LLM.
The expansion model is given the full list of KB categories so it can map vague life situations to concrete financial topics. This is the bridge between how users think ("I'm getting older, what should I start considering financially?") and how the knowledge base is structured (specific concepts with specific names).
Decision 3: Two-Stage Similarity Filtering
Vector similarity search returns a ranked list of concepts, but the similarity scores themselves don't have a natural threshold. A score of 0.45 might be the best match for a niche query or a poor match for a common one.
We use a two-stage approach:
Floor threshold (0.30): The database query casts a wide net, fetching 2× the target count with a low minimum similarity. This maximises recall - we'd rather have too many candidates than miss a relevant concept.
Quality threshold (0.50): Application-level filtering keeps only results above a meaningful quality bar. This is where precision happens.
Minimum guarantee (3): If the quality filter yields fewer than 3 results, we fall back to the top 3 by raw similarity. This prevents the retriever from returning nothing for unusual or edge-case queries.
The database-level search executes in under 200ms thanks to HNSW indexing on the pgvector embedding column. The total retrieval pipeline - including query analysis and potential expansion - takes about 4 seconds for specific queries.
Decision 4: Source-Aware Context Assembly
Retrieval operates at the concept level - the vector search finds relevant concepts, and a second query fetches their full data (including all atomic units) from the database. The final stage then extracts the individual atomic units from within each concept, filters them, and assembles structured context for the LLM.
One subtle but important decision in this assembly: atomic units are grouped by source URL, not just by concept.
Why? Because the same concept can contain units from different gov.uk pages, and those pages often address different audiences or scenarios. Student finance rules for part-time students come from a different page than rules for full-time students. Grouping by source preserves these contextual distinctions, preventing the LLM from conflating rules that apply to different situations.
The assembler also enforces a token budget (8,000 tokens by default), filters out historical units unless specifically relevant, and returns source URLs separately so the UI can display proper citations.
Integration: Agent-Based, Not Simple RAG
Agent Architecture
This is where our approach diverges most from the standard RAG pattern.
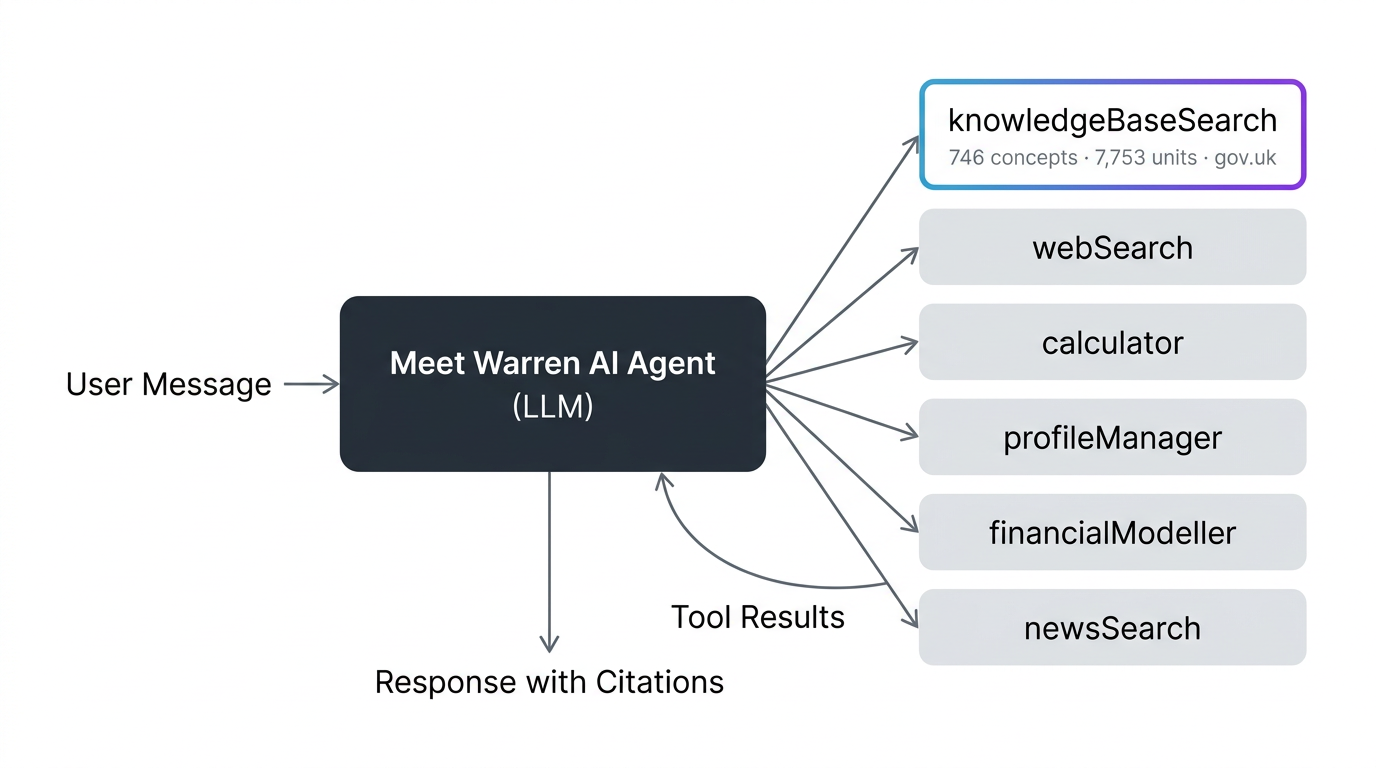
In a typical RAG system, every user message triggers a retrieval step. The retrieved context is prepended to the conversation, and the LLM generates a response that incorporates it. This is always-on - the knowledge base is consulted whether or not the query needs it.
Meet Warren uses agent-based tool calling. The knowledge base is registered as a tool - knowledgeBaseSearch - alongside 20 other tools (web search, calculator, profile management, financial modelling, news). The LLM decides when to call it.
The tool description tells the LLM exactly what the knowledge base covers:
Search our verified UK financial knowledge base for accurate, authoritative gov.uk information. This knowledge base covers: ISAs and Junior ISAs, Pensions, State Pension, Income Tax, Capital Gains Tax, Inheritance Tax, National Insurance, Student Finance, Child Benefit, Tax-Free Childcare, Self Assessment, Tax on Savings and Investments, Government Benefits...
The system prompt instructs:
Whenever the user's question involves or could involve specific UK financial rules, limits, thresholds, allowances, eligibility criteria, tax rates, or government schemes - ALWAYS call knowledgeBaseSearch first, even if you believe you already know the answer.
This means:
"What's the ISA allowance?" → KB called (financial regulation)
"How's my plan looking?" → KB not called (plan review uses different tools)
"What's 15% of £45,000?" → KB not called (calculator tool)
"Good morning!" → KB not called (conversational, no tools needed)
The advantages over always-on RAG:
Latency: Queries that don't need the KB skip the 4-second retrieval entirely
Context efficiency: The LLM's context window isn't loaded with irrelevant financial regulations when the user is asking about their spending
Composability: The LLM can call KB alongside other tools - retrieve pension rules, then run a calculator on the numbers, then update the user's profile
Flexibility: Adding new knowledge domains means adding tool descriptions, not rewiring the retrieval pipeline
This design places an important responsibility on the model: knowing when to reach for the knowledge base. Getting this right means the difference between a response grounded in gov.uk and one relying on training data alone, which naturally makes evaluation an equal priority alongside building the knowledge base itself.
Evaluation: Measuring What Matters
For an agent-based system, the first question isn't "does the knowledge base contain the right information?" - it's "does the model actually call the knowledge base when it should?"
We built an evaluation framework that tests the LLM's tool-calling behaviour in isolation: same model, same system prompt, same tool definitions, same temperature as production - but without executing the tools. We observe whether the model decides to call knowledgeBaseSearch and compare against expected labels across 92 test cases (queries that should trigger KB, queries that shouldn't, and ambiguous edge cases).
Precision sits at 97% - when the model calls the knowledge base, it's almost always correct to do so. Overall hit rate accuracy is around 70%, and we're actively iterating on recall through prompt engineering, tool description, and evaluation cycles. The framework supports multi-run consistency testing, making it straightforward to measure the impact of prompt changes before deploying them.
What's Next
The knowledge base is in production and actively evolving:
Deepening evaluation. Our hit rate evaluation already measures whether the model calls KB correctly. We're now adding two further layers: retrieval relevance scoring (are the returned concepts the best ones for the query?) and answer accuracy testing against questions modelled on the UK's Chartered Insurance Institute examination standards (such as R03 and R04).
Broadening coverage. The current 23 categories cover the core of UK personal finance. We're progressively expanding into business taxation, self-employment, more granular benefit eligibility rules, and more complex personal finance topics.
Automated freshness. Our superseding pipeline already handles the mechanics of temporal updates as regulations change each tax year. We're now building automated change detection that periodically monitors gov.uk sources and flags concepts that may need refreshing.
Personalised retrieval. Retrieval today is query-driven and conversation-aware. The next evolution is incorporating user profile context - age, income, goals - to influence retrieval ranking, surfacing pension rules for users approaching retirement or student finance information for younger users before they ask.
Summary
We started with a specific problem: LLMs are unreliable for UK financial regulations. They hallucinate numbers, serve stale information, and can't cite sources.
We built a concept-based knowledge base - 746 concepts, 7,753 atomic units, all sourced from gov.uk with explicit temporal metadata and source attribution. We designed an extraction pipeline with strict taxonomy enforcement and a superseding detection system that tracks how regulations change over time. We built a retriever that analyses queries before searching, expands vague questions into specific lookups, and filters results through two similarity thresholds. And we integrated it as an agent tool - letting the LLM decide when to consult the knowledge base rather than forcing retrieval on every message.
Our evaluation shows 97% precision on tool-calling decisions, with overall hit rate accuracy around 70% and improving through systematic prompt engineering.
The broader lesson: for domain-specific, regulation-heavy applications, the quality of your knowledge layer matters more than the capability of your model. A curated, structured knowledge base with explicit provenance and temporal awareness produces better answers than a more powerful LLM working from its training data alone.